
处理 OP_READ 事件
前言
在前两篇文章《处理 OP_CONNECT 事件》和《处理 OP_ACCEPT 事件》中,我们讲解了客户端和服务端如何成功建立一个 TCP 连接。通信双方成功建立 TCP 连接(三次握手完成)后,便开始进行数据的收发。
因此,本文以及《处理 OP_WRITE 事件》 将分别讲解网络数据的接收和发送。这两种 IO 操作主要与 NioSocketChannel 相关。
当 NioServerSocketChannel 成功接受客户端连接后,它会将该连接生成的新 NioSocketChannel 注册到 Sub Reactor,并注册 OP_READ 操作。OP_WRITE 操作并不会直接被注册,只有在以下情况下才会注册:
- 当 Netty 向
Channel写入数据时,也就是将用户态缓冲区的数据写入 IO。如果 TCP 缓冲区已满,无法继续写入数据时,OP_WRITE事件才会被注册。
当 OP_WRITE 事件触发时,Netty 会捕获该事件,并继续执行 flush(刷新数据)。
注意: 从本文开始,将涉及大量 ByteBuf 相关内容,建议先阅读本书第四部分【内存管理机制】。
接下来,我们将直接进入今天的主题,探讨 Netty 是如何处理 OP_READ 事件,并高效接收网络数据的。
Sub Reactor 处理 OP_READ 事件流程总览

客户端发起系统 IO 调用,向服务端发送数据后,网络数据会经过网卡,并经过内核协议栈的处理,最终到达 Socket 的接收缓冲区。当 Sub Reactor 轮询到 NioSocketChannel 上的 OP_READ 事件就绪时,Sub Reactor 线程将从 JDK Selector 的阻塞轮询 API selector.select(timeoutMillis) 调用中返回,转而处理 NioSocketChannel 上的 OP_READ 事件。
注意
这里的 Reactor 为负责处理客户端连接的 Sub Reactor。连接的类型为 NioSocketChannel,处理的事件为 OP_READ 事件。
在之前的文章中,笔者已经多次强调,Reactor 在处理 Channel 上的 IO 事件的入口函数为 NioEventLoop#processSelectedKey。
public final class NioEventLoop extends SingleThreadEventLoop {
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
// ..............省略.................
try {
int readyOps = k.readyOps();
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
// ..............处理 OP_CONNECT 事件.................
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
// ..............处理 OP_WRITE 事件.................
}
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
// 本文重点处理 OP_ACCEPT 事件
unsafe.read();
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
}需要重点强调的是,当前的执行线程已经变成了 Sub Reactor,而 Sub Reactor 上注册的正是 Netty 客户端 NioSocketChannel,负责处理连接上的读写事件。因此,这里入口函数的参数 AbstractNioChannel ch 就是 IO 就绪的客户端连接 NioSocketChannel。
通过 ch.unsafe() 获取到的 NioUnsafe 操作类正是 NioSocketChannel 中对底层 JDK NIO SocketChannel 的 Unsafe 底层操作类。实现类型为 NioByteUnsafe,定义在下图继承结构中的 AbstractNioByteChannel 父类中。中。

下面我们到NioByteUnsafe#read方法中来看下 Netty 对OP_READ事件的具体处理过程:
接收网络数据流程总览
我们直接按照老规矩,先从整体上把整个 OP_READ 事件的逻辑处理框架提取出来,让大家先总体俯视下流程全貌,然后在针对每个核心点位进行各个击破。

流程中相关置灰的步骤为 Netty 处理连接关闭时的逻辑,和本文主旨无关,我们这里暂时忽略,等后续笔者介绍连接关闭时,会单独开一篇文章详细为大家介绍。
从上面这张 Netty 接收网络数据总体流程图可以看出 NioSocketChannel 在接收网络数据的整个流程和我们在上篇文章《处理 OP_ACCEPT 事件》中介绍的 NioServerSocketChannel 在接收客户端连接时的流程在总体框架上是一样的。
在接收网络数据的过程中,NioSocketChannel 也是通过一个 do {...} while(...) 循环的 read loop 不断循环读取连接 NioSocketChannel 上的数据。
同样,在 NioSocketChannel 读取连接数据的 read loop 中,也受到最大读取次数的限制。默认配置最多只能读取 16 次,超过 16 次时,无论此时 NioSocketChannel 中是否还有数据可读,都无法继续进行读取。
此处 read loop 循环的最大读取次数可以在启动配置类 ServerBootstrap 中,通过 ChannelOption.MAX_MESSAGES_PER_READ 选项进行设置,默认为 16。
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.MAX_MESSAGES_PER_READ, 自定义次数)为什么限制 read loop 的最大读取次数?
在 Netty 中,限制 read loop 的最大读取次数是出于对整体架构的考量。虽然我们可以在 read loop 中一次性读取所有数据,但这并不是最佳实践。
在前面的文章中,我们提到 Netty 的 IO 模型采用主从 Reactor 线程组模型。在 Sub Reactor Group 中包含多个 Sub Reactor,专门用于监听和处理客户端连接上的 IO 事件。为了高效、有序地处理所有客户端连接的读写事件,Netty 将服务端承载的全部客户端连接分摊到多个 Sub Reactor 中进行处理,这样可以保证 Channel 上 IO 处理的线程安全性。
在这个模型中,一个 Channel 只能分配给一个固定的 Reactor。一个 Reactor 负责处理多个 Channel 上的 IO 就绪事件,Reactor 与 Channel 之间的对应关系如下图所示:

而在一个 Sub Reactor 上注册了多个 NioSocketChannel 后,Netty 不可能在单个 NioSocketChannel 上无限制地处理数据。为了将读取数据的机会均匀分摊给其他 NioSocketChannel,因此需要限定每个 NioSocketChannel 上的最大读取次数。
此外,Sub Reactor 除了需要监听和处理所有注册在其上的 NioSocketChannel 的 IO 就绪事件外,还需要腾出事件来处理用户线程提交的异步任务。从这一点来看,Netty 也不会一直停留在 NioSocketChannel 的 IO 处理上。因此,限制 read loop 的最大读取次数是非常必要的。
基于这个原因,在 read loop 循环中,每当通过 doReadBytes 方法从 NioSocketChannel 中读取到数据时(方法返回值大于 0,并记录在 allocHandle.lastBytesRead 中),都需要通过 allocHandle.incMessagesRead(1) 方法统计已经读取的次数。当达到 16 次时,无论 NioSocketChannel 是否还有数据可读,都需要在 read loop 的末尾退出循环,转而执行 Sub Reactor 上的异步任务以及其他 NioSocketChannel 上的 IO 就绪事件。这种做法确保了事件的平均分配,保证了资源的合理利用。
public abstract class MaxMessageHandle implements ExtendedHandle {
//read loop总共读取了多少次
private int totalMessages;
@Override
public final void incMessagesRead(int amt) {
totalMessages += amt;
}
}本次 read loop 读取到的数据大小会记录在allocHandle.lastBytesRead中
public abstract class MaxMessageHandle implements ExtendedHandle {
//本次read loop读取到的字节数
private int lastBytesRead;
//整个read loop循环总共读取的字节数
private int totalBytesRead;
@Override
public void lastBytesRead(int bytes) {
lastBytesRead = bytes;
if (bytes > 0) {
totalBytesRead += bytes;
}
}
}lastBytesRead < 0:表示客户端主动发起了连接关闭流程,Netty 开始连接关闭处理流程。这个情况与本文的主旨无关,暂时不予讨论。后面笔者会专门用一篇文章详细解读关闭流程。lastBytesRead = 0:表示当前NioSocketChannel上的数据已经全部读取完毕,没有数据可读了。本次 OP_READ 事件圆满处理完毕,可以愉快地退出read loop。lastBytesRead > 0:表示在本次read loop中从NioSocketChannel中读取到了数据。此时会在NioSocketChannel的 pipeline 中触发 ChannelRead 事件,进而在 pipeline 中负责 IO 处理的 ChannelHandler 中响应并处理网络请求。

public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
.......处理网络请求,比如解码,反序列化等操作.......
}
}最后,在 read loop 循环的末尾会调用 allocHandle.continueReading() 来判断是否结束本次 read loop 循环。这里的结束循环条件的判断比在介绍 NioServerSocketChannel 接收连接时的判断条件复杂得多。笔者会在文章后面的细节部分对此判断条件进行详细解析,这里大家只需要把握总体核心流程,不必关注太多细节。
总体上,在 NioSocketChannel 中读取网络数据的 read loop 循环结束条件是下述之一:
- 当前
NioSocketChannel中的数据已经全部读取完毕,则退出循环。 - 本轮 read loop 如果没有读到任何数据,则退出循环。
- read loop 的读取次数达到 16 次,退出循环。
当满足这些 read loop 退出条件之后,Sub Reactor 线程就会退出循环,随后调用 allocHandle.readComplete() 方法,根据本轮 read loop 总共读取到的字节数 totalBytesRead 来决定是否对用于接收下一轮 OP_READ 事件数据的 ByteBuffer 进行扩容或缩容。
最后,在 NioSocketChannel 的 pipeline 中触发 ChannelReadComplete 事件,通知 ChannelHandler 本次 OP_READ 事件已经处理完毕。

public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
.......处理网络请求,比如解码,反序列化等操作.......
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
......本次OP_READ事件处理完毕.......
......决定是否向客户端响应处理结果......
}
}ChannelRead 与 ChannelReadComplete 事件的区别
有些小伙伴可能对 Netty 中一些传播事件触发的时机,或者事件之间的区别理解得不是很清楚,概念容易混淆。在后面的文章中,笔者也会从源码的角度出发,给大家讲清楚 Netty 中定义的所有异步事件,以及这些事件之间的区别、联系和触发时机、传播机制。
在这里,我们主要探讨本文主题中涉及到的两个事件:ChannelRead 事件与 ChannelReadComplete 事件。从上述介绍的 Netty 接收网络数据流程总览中,我们可以看出这两个事件是不同的,但对于刚接触 Netty 的小伙伴来说,从命名上乍一看感觉又差不多。
下面我们来看这两个事件之间的差别:
Netty 服务端对一次 OP_READ 事件的处理,会在一个 do { ... } while() 循环的 read loop 中分多次从客户端的 NioSocketChannel 中读取网络数据。每次读取时,我们分配的 ByteBuffer 的初始容量为 2048。
- ChannelRead 事件:每次循环读取一次数据,就会触发一次
ChannelRead事件。本次最多读取的字节数受限于 read loop 循环开始时分配的DirectByteBuffer容量。这个容量会动态调整,后续文章中笔者会详细介绍。 - ChannelReadComplete 事件:当读取不到数据,或者不满足
continueReading的任意一个条件时,会退出 read loop,这时会触发ChannelReadComplete事件,表示本次OP_READ事件处理完毕。
需要特别注意的是,触发 ChannelReadComplete 事件并不代表 NioSocketChannel 中的数据已经读取完了,只能说明本次 OP_READ 事件处理完毕。因为有可能是客户端发送的数据太多,Netty 读了 16 次还没读完,那就只能等到下次 OP_READ 事件到来的时候再进行读取。
以上内容就是 Netty 在接收客户端发送网络数据的全部核心逻辑。目前为止我们还未涉及到这部分的主干核心源码,笔者想的是先给大家把核心逻辑讲解清楚之后,这样理解起来核心主干源码会更加清晰透彻。
经过前边对网络数据接收的核心逻辑介绍,笔者在把这张流程图放出来,大家可以结合这张图在来回想下主干核心逻辑。
下面笔者会结合这张流程图,给大家把这部分的核心主干源码框架展现出来,大家可以将我们介绍过的核心逻辑与主干源码做个一一对应,还是那句老话,我们要从主干框架层面把握整体处理流程,不需要读懂每一行代码,文章后续笔者会将这个过程中涉及到的核心点位给大家拆开来各个击破!!
源码核心框架总览
@Override
public final void read() {
final ChannelConfig config = config();
...............处理半关闭相关代码省略...............
//获取NioSocketChannel的pipeline
final ChannelPipeline pipeline = pipeline();
//PooledByteBufAllocator 具体用于实际分配ByteBuf的分配器
final ByteBufAllocator allocator = config.getAllocator();
//自适应ByteBuf分配器 AdaptiveRecvByteBufAllocator ,用于动态调节ByteBuf容量
//需要与具体的ByteBuf分配器配合使用 比如这里的PooledByteBufAllocator
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
//allocHandler用于统计每次读取数据的大小,方便下次分配合适大小的ByteBuf
//重置清除上次的统计指标
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
//利用PooledByteBufAllocator分配合适大小的byteBuf 初始大小为2048
byteBuf = allocHandle.allocate(allocator);
//记录本次读取了多少字节数
allocHandle.lastBytesRead(doReadBytes(byteBuf));
//如果本次没有读取到任何字节,则退出循环 进行下一轮事件轮询
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
......表示客户端发起连接关闭.....
}
break;
}
//read loop读取数据次数+1
allocHandle.incMessagesRead(1);
//客户端NioSocketChannel的pipeline中触发ChannelRead事件
pipeline.fireChannelRead(byteBuf);
//解除本次读取数据分配的ByteBuffer引用,方便下一轮read loop分配
byteBuf = null;
} while (allocHandle.continueReading());//判断是否应该继续read loop
//根据本次 read loop 总共读取的字节数,决定下次是否扩容或者缩容
allocHandle.readComplete();
//在 NioSocketChannel 的 pipeline 中触发 ChannelReadComplete 事件,表示一次 read 事件处理完毕
//但这并不表示 客户端发送来的数据已经全部读完,因为如果数据太多的话,这里只会读取 16 次,剩下的会等到下次 read 事件到来后在处理
pipeline.fireChannelReadComplete();
.........省略连接关闭流程处理.........
} catch (Throwable t) {
...............省略...............
} finally {
...............省略...............
}
}
}这里再次强调,当前执行线程为 Sub Reactor 线程,处理连接数据读取逻辑是在 NioSocketChannel 中。
首先,通过 config() 获取客户端 NioSocketChannel 的 Channel 配置类 NioSocketChannelConfig。接着,通过 pipeline() 获取 NioSocketChannel 的 pipeline。在 Netty 服务端模板 EchoServer 所举的示例中,NioSocketChannel 的 pipeline 中只有一个 EchoChannelHandler。

分配 DirectByteBuffer 接收网络数据
Sub Reactor 在接收 NioSocketChannel 上的 IO 数据时,都会分配一个 ByteBuffer 用来存放接收到的 IO 数据。
这里可能会让大家感到疑惑,为什么在 NioSocketChannel 接收数据时会有两个 ByteBuffer 分配器?一个是 ByteBufAllocator,另一个是 RecvByteBufAllocator。
final ByteBufAllocator allocator = config.getAllocator();
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();在上篇文章《处理 OP_ACCEPT 事件》中,笔者为了阐述上篇文章中提到的 Netty 在接收网络连接时的 Bug 时,简单和大家介绍了下这个RecvByteBufAllocator。
在这两个 ByteBuffer 各自的区别和联系如下:
ByteBufAllocator:这是 Netty 的一个接口,用于分配ByteBuf的实例。它负责在应用层为数据的处理分配合适的内存。通过ByteBufAllocator,可以获得不同类型的ByteBuf,例如堆内存或直接内存,适用于不同的场景。RecvByteBufAllocator:这个接口专门用于接收数据时的内存分配。它的职责是根据网络接收的流量动态调整内存的分配策略,从而提高性能。在上篇文章提到的NioServerSocketChannelConfig中,这里的RecvByteBufAllocator类型为ServerChannelRecvByteBufAllocator,它特别为服务端通道的接收设计。
总结来说,ByteBufAllocator 主要用于内存的分配,而 RecvByteBufAllocator 则用于接收数据时的动态内存分配策略。两者共同协作,以提高 Netty 在处理 IO 数据时的性能和灵活性。
而在本文中 NioSocketChannelConfig 中的 RecvByteBufAllocator 类型为 AdaptiveRecvByteBufAllocator。

所以这里 recvBufAllocHandle() 获得的 RecvByteBufAllocator 为 AdaptiveRecvByteBufAllocator。顾名思义,这种类型的 RecvByteBufAllocator 可以根据 NioSocketChannel 上每次到来的 IO 数据大小,自适应动态调整 ByteBuffer 的容量。
对于客户端 NioSocketChannel 来说,它内部包含的 IO 数据是客户端发送来的网络数据,长度是不定的。因此,需要一个可以根据每次 IO 数据的大小自适应动态调整容量的 ByteBuffer 来接收。
如果我们把用于接收数据的 ByteBuffer 看作一个桶,那么小数据用大桶装或大数据用小桶装肯定是不合适的。我们需要根据接收数据的大小动态调整桶的容量。而 AdaptiveRecvByteBufAllocator 的作用就是根据每次接收数据的容量大小动态调整 ByteBuffer 的容量。
现在 RecvByteBufAllocator 的概念已经解释清楚了,接下来我们继续看 ByteBufAllocator。
需要注意的是,AdaptiveRecvByteBufAllocator 并不会真正地去分配 ByteBuffer,它只是负责动态调整分配 ByteBuffer 的大小。
真正执行内存分配动作的是类型为 PooledByteBufAllocator 的 ByteBufAllocator。它会根据 AdaptiveRecvByteBufAllocator 动态调整出来的大小去真正申请内存分配 ByteBuffer。
PooledByteBufAllocator 是 Netty 中的内存池,用来管理堆外内存 DirectByteBuffer。
最后,AdaptiveRecvByteBufAllocator 中的 allocHandle 在【TODO】上篇文章中我们也介绍过,它的实际类型为 MaxMessageHandle。
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
@Override
public Handle newHandle() {
return new HandleImpl(minIndex, maxIndex, initial);
}
private final class HandleImpl extends MaxMessageHandle {
.................省略................
}
}在 MaxMessageHandle 中包含了用于动态调整 ByteBuffer 容量的统计指标。
public abstract class MaxMessageHandle implements ExtendedHandle {
private ChannelConfig config;
//用于控制每次read loop里最大可以循环读取的次数,默认为16次
//可在启动配置类ServerBootstrap中通过ChannelOption.MAX_MESSAGES_PER_READ选项设置。
private int maxMessagePerRead;
//用于统计read loop中总共接收的连接个数,NioSocketChannel中表示读取数据的次数
//每次read loop循环后会调用allocHandle.incMessagesRead增加记录接收到的连接个数
private int totalMessages;
//用于统计在read loop中总共接收到客户端连接上的数据大小
private int totalBytesRead;
//表示本次read loop 尝试读取多少字节,byteBuffer剩余可写的字节数
private int attemptedBytesRead;
//本次read loop读取到的字节数
private int lastBytesRead;
//预计下一次分配buffer的容量,初始:2048
private int nextReceiveBufferSize;
...........省略.............
}在每轮 read loop 开始之前,都会调用 allocHandle.reset(config) 来重置并清空上一轮 read loop 的统计指标。
@Override
public void reset(ChannelConfig config) {
this.config = config;
//默认每次最多读取16次
maxMessagePerRead = maxMessagesPerRead();
totalMessages = totalBytesRead = 0;
}在每次开始从 NioSocketChannel 中读取数据之前,需要利用 PooledByteBufAllocator 在内存池中为 ByteBuffer 分配内存,默认初始化大小为 2048,这个容量由 guess() 方法决定。
byteBuf = allocHandle.allocate(allocator);
@Override
public ByteBuf allocate(ByteBufAllocator alloc) {
return alloc.ioBuffer(guess());
}
@Override
public int guess() {
//预计下一次分配buffer的容量,一开始为2048
return nextReceiveBufferSize;
}在每次通过 doReadBytes 从 NioSocketChannel 中读取到数据后,都会调用 allocHandle.lastBytesRead(doReadBytes(byteBuf)) 来记录本次读取的字节数,并统计本轮 read loop 目前总共读取了多少字节。
@Override
public void lastBytesRead(int bytes) {
lastBytesRead = bytes;
if (bytes > 0) {
totalBytesRead += bytes;
}
}每次循环从 NioSocketChannel 中读取数据之后,都会调用 allocHandle.incMessagesRead(1) 来统计当前已经读取的次数。如果超过了最大读取限制(此时为 16 次),就需要退出 read loop,以处理其他 NioSocketChannel 上的 IO 事件。
@Override
public final void incMessagesRead(int amt) {
totalMessages += amt;
}在每次 read loop 循环的末尾,都需要通过调用 allocHandle.continueReading() 来判断是否继续 read loop 循环读取 NioSocketChannel 中的数据。
@Override
public boolean continueReading() {
return continueReading(defaultMaybeMoreSupplier);
}
private final UncheckedBooleanSupplier defaultMaybeMoreSupplier = new UncheckedBooleanSupplier() {
@Override
public boolean get() {
//判断本次读取byteBuffer是否满载而归
return attemptedBytesRead == lastBytesRead;
}
};
@Override
public boolean continueReading(UncheckedBooleanSupplier maybeMoreDataSupplier) {
return config.isAutoRead() &&
(!respectMaybeMoreData || maybeMoreDataSupplier.get()) &&
totalMessages < maxMessagePerRead &&
totalBytesRead > 0;
}attemptedBytesRead:表示当前ByteBuffer预计尝试要写入的字节数。lastBytesRead:表示本次read loop真实读取到的字节数。
defaultMaybeMoreSupplier 用于判断经过本次 read loop 读取数据后,ByteBuffer 是否满载而归。如果是满载而归(attemptedBytesRead == lastBytesRead),表明可能 NioSocketChannel 里还有数据;如果不是满载而归,则表明 NioSocketChannel 里已经没有数据了。
是否继续进行 read loop 需要 同时 满足以下几个条件:
totalMessages < maxMessagePerRead:当前读取次数是否已经超过16 次,如果超过,就退出do(...)while()循环,进行下一轮OP_READ事件的轮询。因为每个 Sub Reactor 管理了多个NioSocketChannel,不能在一个NioSocketChannel上占用太多时间,要将机会均匀地分配给 Sub Reactor 所管理的所有NioSocketChannel。totalBytesRead > 0:本次OP_READ事件处理是否读取到了数据,如果没有数据可读,直接退出read loop。!respectMaybeMoreData || maybeMoreDataSupplier.get():这个条件比较复杂,它通过respectMaybeMoreData字段来控制NioSocketChannel中可能还有数据可读的情况下该如何处理。maybeMoreDataSupplier.get():true表示本次读取从NioSocketChannel中读取数据,ByteBuffer满载而归,说明可能NioSocketChannel中还有数据没读完;false表示ByteBuffer还没有装满,说明NioSocketChannel中已经没有数据可读了。respectMaybeMoreData = true:表示要对可能还有更多数据进行处理的这种情况认真对待。如果本次循环读取到的数据已经装满ByteBuffer,表示后面可能还有数据,那么就要继续进行读取;如果ByteBuffer还没装满,表示已经没有数据可读,则退出循环。respectMaybeMoreData = false:表示对可能还有更多数据的这种情况不认真对待。不管本次循环读取数据ByteBuffer是否满载而归,都要继续进行读取,直到读取不到数据再退出循环,属于无脑读取。
只要同时满足以上三个条件,read loop 就会继续进行,从 NioSocketChannel 中读取数据,直到读取不到数据或不满足任意一个条件为止。
从 NioSocketChannel 中读取数据
public class NioSocketChannel extends AbstractNioByteChannel implements io.netty.channel.socket.SocketChannel {
@Override
protected int doReadBytes(ByteBuf byteBuf) throws Exception {
final RecvByteBufAllocator.Handle allocHandle = unsafe().recvBufAllocHandle();
allocHandle.attemptedBytesRead(byteBuf.writableBytes());
return byteBuf.writeBytes(javaChannel(), allocHandle.attemptedBytesRead());
}
}这里会直接调用底层 JDK NIO 的 SocketChannel#read 方法,将数据读取到 DirectByteBuffer 中。读取数据的大小为本次分配的 DirectByteBuffer 容量,初始为 2048。
ByteBuffer 动态自适应扩缩容机制
由于我们一开始并不知道客户端会发送多大的网络数据,因此这里先利用 PooledByteBufAllocator 分配一个初始容量为 2048 的 DirectByteBuffer 用于接收数据。
byteBuf = allocHandle.allocate(allocator);这就好比我们需要拿着一个桶去排队装水,但第一次去装的时候,我们并不知道管理员会给我们分配多少水。桶拿大了也不合适,拿小了也不合适,于是我们就先预估一个差不多容量的桶。如果分配的多了,下次我们就拿更大一点的桶;如果分配少了,下次我们就拿一个小点的桶。
在这种场景下,我们需要 ByteBuffer 能够自动根据每次网络数据的大小来动态自适应调整自己的容量。
而 ByteBuffer 动态自适应扩缩容机制依赖于 AdaptiveRecvByteBufAllocator 类的实现。让我们先回到 AdaptiveRecvByteBufAllocator 类的创建起点开始说起。
AdaptiveRecvByteBufAllocator 的创建
在前文《处理 OP_ACCEPT 事件》中,我们提到,当 Main Reactor 监听到 OP_ACCEPT 事件活跃后,会在 NioServerSocketChannel 中接受完成三次握手的客户端连接,并创建 NioSocketChannel。伴随着 NioSocketChannel 的创建,其对应的配置类 NioSocketChannelConfig 也会随之创建。
public NioSocketChannel(Channel parent, SocketChannel socket) {
super(parent, socket);
config = new NioSocketChannelConfig(this, socket.socket());
}最终会在 NioSocketChannelConfig 的父类 DefaultChannelConfig 的构造器中创建 AdaptiveRecvByteBufAllocator,并将其保存在 RecvByteBufAllocator rcvBufAllocator 字段中。
public class DefaultChannelConfig implements ChannelConfig {
//用于Channel接收数据用的buffer分配器 AdaptiveRecvByteBufAllocator
private volatile RecvByteBufAllocator rcvBufAllocator;
public DefaultChannelConfig(Channel channel) {
this(channel, new AdaptiveRecvByteBufAllocator());
}
}在 new AdaptiveRecvByteBufAllocator() 创建 AdaptiveRecvByteBufAllocator 类实例的时候,会先触发 AdaptiveRecvByteBufAllocator 类的初始化。
我们先来看一下 AdaptiveRecvByteBufAllocator 类的初始化都做了些什么事情:
AdaptiveRecvByteBufAllocator 类的初始化
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
//扩容步长
private static final int INDEX_INCREMENT = 4;
//缩容步长
private static final int INDEX_DECREMENT = 1;
//RecvBuf分配容量表(扩缩容索引表)按照表中记录的容量大小进行扩缩容
private static final int[] SIZE_TABLE;
static {
//初始化RecvBuf容量分配表
List<Integer> sizeTable = new ArrayList<Integer>();
//当分配容量小于512时,扩容单位为16递增
for (int i = 16; i < 512; i += 16) {
sizeTable.add(i);
}
//当分配容量大于512时,扩容单位为一倍
for (int i = 512; i > 0; i <<= 1) {
sizeTable.add(i);
}
//初始化RecbBuf扩缩容索引表
SIZE_TABLE = new int[sizeTable.size()];
for (int i = 0; i < SIZE_TABLE.length; i ++) {
SIZE_TABLE[i] = sizeTable.get(i);
}
}
}AdaptiveRecvByteBufAllocator 主要的作用就是为接收数据的 ByteBuffer 进行扩容和缩容。那么,每次如何扩容?扩容多少?怎么缩容?缩容多少呢?这四个问题将是本小节笔者要为大家解答的内容。
在 Netty 中定义了一个 int 类型的数组 SIZE_TABLE 来存储每个扩容单位对应的容量大小,建立起扩缩容的容量索引表。每次扩容多少,缩容多少,全部记录在这个容量索引表中。
在 AdaptiveRecvByteBufAllocator 类初始化的时候,会在 static{} 静态代码块中对扩缩容索引表 SIZE_TABLE 进行初始化。
从源码中我们可以看出,SIZE_TABLE 的初始化分为两个部分:
- 当索引容量小于
512时,SIZE_TABLE中定义的容量索引是从16开始按16递增。

- 当索引容量大于
512时,SIZE_TABLE中定义的容量索引是按前一个索引容量的 2 倍递增。

扩缩容逻辑
现在扩缩容索引表 SIZE_TABLE 已经初始化完毕了,那么当我们需要对 ByteBuffer 进行扩容或者缩容的时候,如何根据 SIZE_TABLE 决定扩容多少或者缩容多少呢?
这就用到了在 AdaptiveRecvByteBufAllocator 类中定义的扩容步长 INDEX_INCREMENT = 4 和缩容步长 INDEX_DECREMENT = 1。
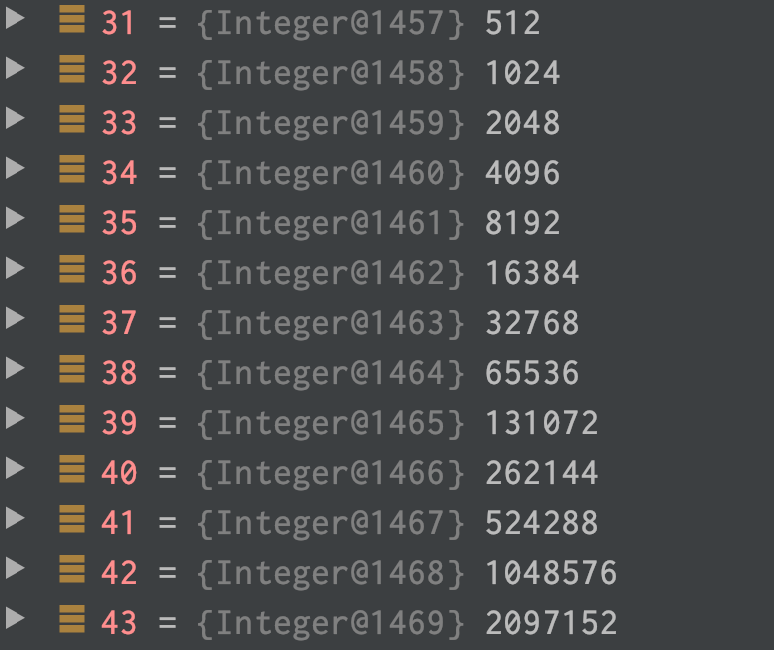
以上面两副扩缩容容量索引表 SIZE_TABLE 中的容量索引展示为例,来介绍一下扩缩容逻辑。假设我们当前 ByteBuffer 的容量索引为 33,对应的容量为 2048。
扩容
当对容量为 2048 的 ByteBuffer 进行扩容时,根据当前的容量索引 index = 33 加上 扩容步长 INDEX_INCREMENT = 4,计算出扩容后的容量索引为 37。那么扩缩容索引表 SIZE_TABLE 下标 37 对应的容量就是本次 ByteBuffer 扩容后的容量,即 SIZE_TABLE[37] = 32768。
缩容
同理,对容量为 2048 的 ByteBuffer 进行缩容时,我们需要用当前容量索引 index = 33 减去 缩容步长 INDEX_DECREMENT = 1,计算出缩容后的容量索引为 32。那么扩缩容索引表 SIZE_TABLE 下标 32 对应的容量就是本次 ByteBuffer 缩容后的容量,即 SIZE_TABLE[32] = 1024。
扩缩容时机
public abstract class AbstractNioByteChannel extends AbstractNioChannel {
@Override
public final void read() {
.........省略......
try {
do {
.........省略......
} while (allocHandle.continueReading());
//根据本次read loop总共读取的字节数,决定下次是否扩容或者缩容
allocHandle.readComplete();
.........省略.........
} catch (Throwable t) {
...............省略...............
} finally {
...............省略...............
}
}
}在每轮 read loop 结束之后,我们都会调用allocHandle.readComplete()来根据在 allocHandle 中统计的在本轮 read loop 中读取字节总大小,来决定在下一轮 read loop 中是否对 DirectByteBuffer 进行扩容或者缩容。
public abstract class MaxMessageHandle implements ExtendedHandle {
@Override
public void readComplete() {
//是否对recvbuf进行扩容缩容
record(totalBytesRead());
}
private void record(int actualReadBytes) {
if (actualReadBytes <= SIZE_TABLE[max(0, index - INDEX_DECREMENT)]) {
if (decreaseNow) {
index = max(index - INDEX_DECREMENT, minIndex);
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false;
} else {
decreaseNow = true;
}
} else if (actualReadBytes >= nextReceiveBufferSize) {
index = min(index + INDEX_INCREMENT, maxIndex);
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false;
}
}
}我们以当前 ByteBuffer 容量为2048,容量索引index = 33为例,对allocHandle的扩容缩容规则进行说明
扩容步长INDEX_INCREMENT = 4,缩容步长INDEX_DECREMENT = 1。
缩容
- 如果本次
OP_READ事件实际读取到的总字节数actualReadBytes在SIZE_TABLE[index - INDEX_DECREMENT]与SIZE_TABLE[index]之间,也就是说如果本轮 read loop 结束之后,总共读取的字节数在[1024, 2048]之间,说明此时分配的ByteBuffer容量正好,不需要进行缩容,也不需要进行扩容。比如本次actualReadBytes = 2000,正好处在1024与2048之间,说明2048的容量正好。 - 如果
actualReadBytes小于等于SIZE_TABLE[index - INDEX_DECREMENT],也就是如果本轮 read loop 结束之后,总共读取的字节数小于等于1024,表示本次读取到的字节数比当前ByteBuffer容量的下一级容量还要小,说明当前ByteBuffer的容量分配得有些大了。此时设置缩容标识decreaseNow = true。当下次OP_READ事件继续满足缩容条件时,开始真正进行缩容。缩容后的容量为SIZE_TABLE[index - INDEX_DECREMENT],但不能小于SIZE_TABLE[minIndex]。
注意
需要满足两次缩容条件才会进行缩容,且缩容步长为 1,缩容过程较为谨慎。
扩容
如果本次 OP_READ事件 处理总共读取的字节数 actualReadBytes 大于等于当前 ByteBuffer 容量 nextReceiveBufferSize 时,说明 ByteBuffer 分配的容量有点小了,需要进行扩容。扩容后的容量为 SIZE_TABLE[index + INDEX_INCREMENT],但不能超过 SIZE_TABLE[maxIndex]。
满足一次扩容条件就进行扩容,并且扩容步长为 4,扩容过程较为奔放。
AdaptiveRecvByteBufAllocator 类的实例化
AdaptiveRecvByteBufAllocator 类的实例化主要是确定 ByteBuffer 的初始容量,以及最小容量和最大容量在扩缩容索引表SIZE_TABLE中的下标:minIndex和maxIndex。
AdaptiveRecvByteBufAllocator 定义了三个关于 ByteBuffer 容量的字段:
DEFAULT_MINIMUM:表示 ByteBuffer 最小的容量,默认为64,也就是无论 ByteBuffer 在怎么缩容,容量也不会低于64。DEFAULT_INITIAL:表示 ByteBuffer 的初始化容量。默认为2048。DEFAULT_MAXIMUM:表示 ByteBuffer 的最大容量,默认为65536,也就是无论 ByteBuffer 在怎么扩容,容量也不会超过65536。
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
static final int DEFAULT_MINIMUM = 64;
static final int DEFAULT_INITIAL = 2048;
static final int DEFAULT_MAXIMUM = 65536;
public AdaptiveRecvByteBufAllocator() {
this(DEFAULT_MINIMUM, DEFAULT_INITIAL, DEFAULT_MAXIMUM);
}
public AdaptiveRecvByteBufAllocator(int minimum, int initial, int maximum) {
.................省略异常检查逻辑.............
//计算minIndex maxIndex
//在SIZE_TABLE中二分查找最小 >= minimum的容量索引 :3
int minIndex = getSizeTableIndex(minimum);
if (SIZE_TABLE[minIndex] < minimum) {
this.minIndex = minIndex + 1;
} else {
this.minIndex = minIndex;
}
//在SIZE_TABLE中二分查找最大 <= maximum的容量索引 :38
int maxIndex = getSizeTableIndex(maximum);
if (SIZE_TABLE[maxIndex] > maximum) {
this.maxIndex = maxIndex - 1;
} else {
this.maxIndex = maxIndex;
}
this.initial = initial;
}
}接下来的事情就是确定最小容量 DEFAULT_MINIMUM 在 SIZE_TABLE 中的下标minIndex,以及最大容量 DEFAULT_MAXIMUM 在 SIZE_TABLE 中的下标maxIndex。
从 AdaptiveRecvByteBufAllocator 类初始化的过程中,我们可以看出 SIZE_TABLE 中存储的数据特征是一个有序的集合。
我们可以通过二分查找在 SIZE_TABLE 中找出第一个容量大于等于 DEFAULT_MINIMUM 的容量索引minIndex。
同理通过二分查找在 SIZE_TABLE 中找出最后一个容量小于等于 DEFAULT_MAXIMUM 的容量索引maxIndex。
根据上一小节关于SIZE_TABLE中容量数据分布的截图,我们可以看出minIndex = 3,maxIndex = 38
二分查找容量索引下标
private static int getSizeTableIndex(final int size) {
for (int low = 0, high = SIZE_TABLE.length - 1;;) {
if (high < low) {
return low;
}
if (high == low) {
return high;
}
int mid = low + high >>> 1;//无符号右移,高位始终补0
int a = SIZE_TABLE[mid];
int b = SIZE_TABLE[mid + 1];
if (size > b) {
low = mid + 1;
} else if (size < a) {
high = mid - 1;
} else if (size == a) {
return mid;
} else {
return mid + 1;
}
}
}经常刷 LeetCode 的小伙伴肯定一眼就看出这个是二分查找的模板了。
它的目的就是根据给定容量,在扩缩容索引表SIZE_TABLE中,通过二分查找找到最贴近给定 size 的容量的索引下标(第一个大于等于 size 的容量)
RecvByteBufAllocator.Handle
前边我们提到,最终动态调整 ByteBuffer 容量的是由 AdaptiveRecvByteBufAllocator 中的 Handler 负责的。我们来看看这个 allocHandle 的创建过程。
protected abstract class AbstractUnsafe implements Unsafe {
private RecvByteBufAllocator.Handle recvHandle;
@Override
public RecvByteBufAllocator.Handle recvBufAllocHandle() {
if (recvHandle == null) {
recvHandle = config().getRecvByteBufAllocator().newHandle();
}
return recvHandle;
}
}从 allocHandle 的获取过程我们看到,最初 allocHandle 的创建是由 AdaptiveRecvByteBufAllocator#newHandle 方法执行的。
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
@Override
public Handle newHandle() {
return new HandleImpl(minIndex, maxIndex, initial);
}
private final class HandleImpl extends MaxMessageHandle {
//最小容量在扩缩容索引表中的index
private final int minIndex;
//最大容量在扩缩容索引表中的index
private final int maxIndex;
//当前容量在扩缩容索引表中的index 初始33 对应容量2048
private int index;
//预计下一次分配buffer的容量,初始:2048
private int nextReceiveBufferSize;
//是否缩容
private boolean decreaseNow;
HandleImpl(int minIndex, int maxIndex, int initial) {
this.minIndex = minIndex;
this.maxIndex = maxIndex;
//在扩缩容索引表中二分查找到最小大于等于initial 的容量
index = getSizeTableIndex(initial);
//2048
nextReceiveBufferSize = SIZE_TABLE[index];
}
.......................省略...................
}
}这里我们看到 Netty 中用于动态调整 ByteBuffer 容量的 allocHandle 的实际类型为 MaxMessageHandle。
下面我们来介绍下 HandleImpl 中的核心字段,它们都与 ByteBuffer 的容量有关:
minIndex:最小容量在扩缩容索引表SIZE_TABLE中的 index。默认是3。maxIndex:最大容量在扩缩容索引表SIZE_TABLE中的 index。默认是38。index:当前容量在扩缩容索引表SIZE_TABLE中的 index。初始是33。nextReceiveBufferSize:预计下一次分配 buffer 的容量,初始为2048。在每次申请内存分配ByteBuffer的时候,采用nextReceiveBufferSize的值指定容量。decreaseNow:是否需要进行缩容。
使用堆外内存为 ByteBuffer 分配内存
AdaptiveRecvByteBufAllocator 类只是负责动态调整 ByteBuffer 的容量,而具体为 ByteBuffer 申请内存空间的是由 PooledByteBufAllocator 负责。
类名前缀 Pooled 的来历
在我们使用 Java 进行日常开发时,为对象分配内存空间通常选择在 JVM 堆中进行,这样做对 Java 开发者特别友好,因为我们只需使用对象,而不必过多关心内存的回收,因为 JVM 堆完全由 Java 虚拟机控制管理,虚拟机会自动回收不再使用的内存。
然而,JVM 在进行垃圾回收时会发生 stop the world,这会对应用程序的性能造成一定影响。
此外,在《从内核角度看 IO 模型》一文中提到,当数据达到网卡时,网卡会通过 DMA 的方式将数据拷贝到内核空间中,这是 第一次拷贝。当用户线程在用户空间发起系统 IO 调用时,CPU 会将内核空间的数据再次拷贝到用户空间,这就是 第二次拷贝。
与此不同的是,当我们在 JVM 中发起 IO 调用时,比如使用 JVM 堆内存读取 Socket 接收缓冲区中的数据时,会多一次内存拷贝。在 第二次拷贝 中,CPU 将数据从内核空间拷贝到用户空间,此时的用户空间在 JVM 角度是 堆外内存,因此还需要将堆外内存中的数据拷贝到 堆内内存 中。这就是 第三次内存拷贝。
同理,当我们在 JVM 中发起 IO 调用向 Socket 发送缓冲区写入数据时,JVM 会先将 IO 数据拷贝到 堆外内存,然后才能发起系统 IO 调用。
那为什么操作系统不直接使用 JVM 的 堆内内存 进行 IO 操作 呢?
因为 JVM 的内存布局和操作系统分配的内存是不一样的,操作系统无法按照 JVM 的规范来读写数据,因此需要在 第三次拷贝 中进行转换,将堆外内存中的数据拷贝到 JVM 堆中。
基于上述内容,在使用 JVM 堆内内存时会产生以下两点性能影响:
- JVM 在垃圾回收堆内内存时,会发生
stop the world导致应用程序卡顿。 - 在进行 IO 操作时,会多产生一次由堆外内存到堆内内存的拷贝。
基于以上两点使用 JVM 堆内内存 对性能造成的影响,于是对性能有卓越追求的 Netty 采用 堆外内存,也就是 DirectBuffer,来为 ByteBuffer 分配内存空间。
采用堆外内存为 ByteBuffer 分配内存的好处包括:
- 堆外内存直接受操作系统管理,不受 JVM 管理,因此 JVM 垃圾回收对应用程序性能的影响消失。
- 网络数据到达后,直接在 堆外内存 上接收,进程读取网络数据时直接在堆外内存中读取,从而避免了 第三次内存拷贝。
因此,Netty 在进行 I/O 操作时使用堆外内存,可以避免数据从 JVM 堆内存到堆外内存的拷贝。但由于堆外内存不受 JVM 管理,因此需要额外关注内存的使用和释放,稍有不慎可能造成内存泄漏。为此,Netty 引入了 内存池 来统一管理 堆外内存。
PooledByteBufAllocator 类的这个前缀 Pooled 就是 内存池 的意思,这个类会使用 Netty 的内存池为 ByteBuffer 分配 堆外内存。
PooledByteBufAllocator 的创建
创建时机
在服务端 NioServerSocketChannel 的配置类 NioServerSocketChannelConfig 以及客户端 NioSocketChannel 的配置类 NioSocketChannelConfig 实例化的时候会触发 PooledByteBufAllocator 的创建。
public class DefaultChannelConfig implements ChannelConfig {
//PooledByteBufAllocator
private volatile ByteBufAllocator allocator = ByteBufAllocator.DEFAULT;
..........省略......
}创建出来的 PooledByteBufAllocator 实例保存在 DefaultChannelConfig 类中的 ByteBufAllocator allocator 字段中。
创建过程
public interface ByteBufAllocator {
ByteBufAllocator DEFAULT = ByteBufUtil.DEFAULT_ALLOCATOR;
..................省略............
}
public final class ByteBufUtil {
static final ByteBufAllocator DEFAULT_ALLOCATOR;
static {
String allocType = SystemPropertyUtil.get(
"io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
ByteBufAllocator alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
DEFAULT_ALLOCATOR = alloc;
...................省略..................
}
}从 ByteBufUtil 类的初始化过程我们可以看出,在为 ByteBuffer 分配内存的时候,是否使用内存池在 Netty 中是可以配置的。
- 通过系统变量
-D io.netty.allocator.type可以配置是否使用内存池为ByteBuffer分配内存。默认情况下是需要使用内存池的,但在安卓系统中默认是不使用内存池的。 - 通过
PooledByteBufAllocator.DEFAULT获取 内存池 ByteBuffer 分配器:
public static final PooledByteBufAllocator DEFAULT =
new PooledByteBufAllocator(PlatformDependent.directBufferPreferred());由于本文的主线是介绍 Sub Reactor 处理 OP_READ 事件的完整过程,因此这里只介绍与主线相关的内容。这里简单说明在接收数据时为什么会使用 PooledByteBufAllocator 来为 ByteBuffer 分配内存。此外,由于内存池的架构设计比较复杂,笔者会在后续单独撰写一篇关于 Netty 内存管理的文章。
总结
本文介绍了 Sub Reactor 线程在处理 OP_READ 事件的整个过程,并深入剖析了 AdaptiveRecvByteBufAllocator 类动态调整 ByteBuffer 容量的原理。
同时也介绍了 Netty 为什么会使用堆外内存来为 ByteBuffer 分配内存,并由此引出了 Netty 的内存池分配器 PooledByteBufAllocator。
在介绍 AdaptiveRecvByteBufAllocator 类和 PooledByteBufAllocator 组合实现动态地为 ByteBuffer 分配容量时,笔者不禁想起了多年前看过的《Effective Java》中第 16 条“复合优于继承”。
Netty 在这里也遵循了这条原则,首先这两个类的设计都是单一的功能:
AdaptiveRecvByteBufAllocator类只负责动态调整ByteBuffer容量,而不涉及具体的内存分配。PooledByteBufAllocator类负责具体的内存分配,采用内存池的方式。
这样的设计使得系统更加灵活,具体的内存分配工作交给具体的 ByteBufAllocator,可以使用内存池的分配方式 PooledByteBufAllocator,也可以选择不使用内存池的分配方式 UnpooledByteBufAllocator。具体的内存可以采用 JVM 堆内内存(HeapBuffer),也可以使用堆外内存(DirectBuffer)。
而 AdaptiveRecvByteBufAllocator 只需关注调整它们的容量,而不需要关心具体的内存分配方式。
最后,通过 io.netty.channel.RecvByteBufAllocator.Handle#allocate 方法灵活组合不同的内存分配方式。这也是装饰模式的一种应用。
byteBuf = allocHandle.allocate(allocator);